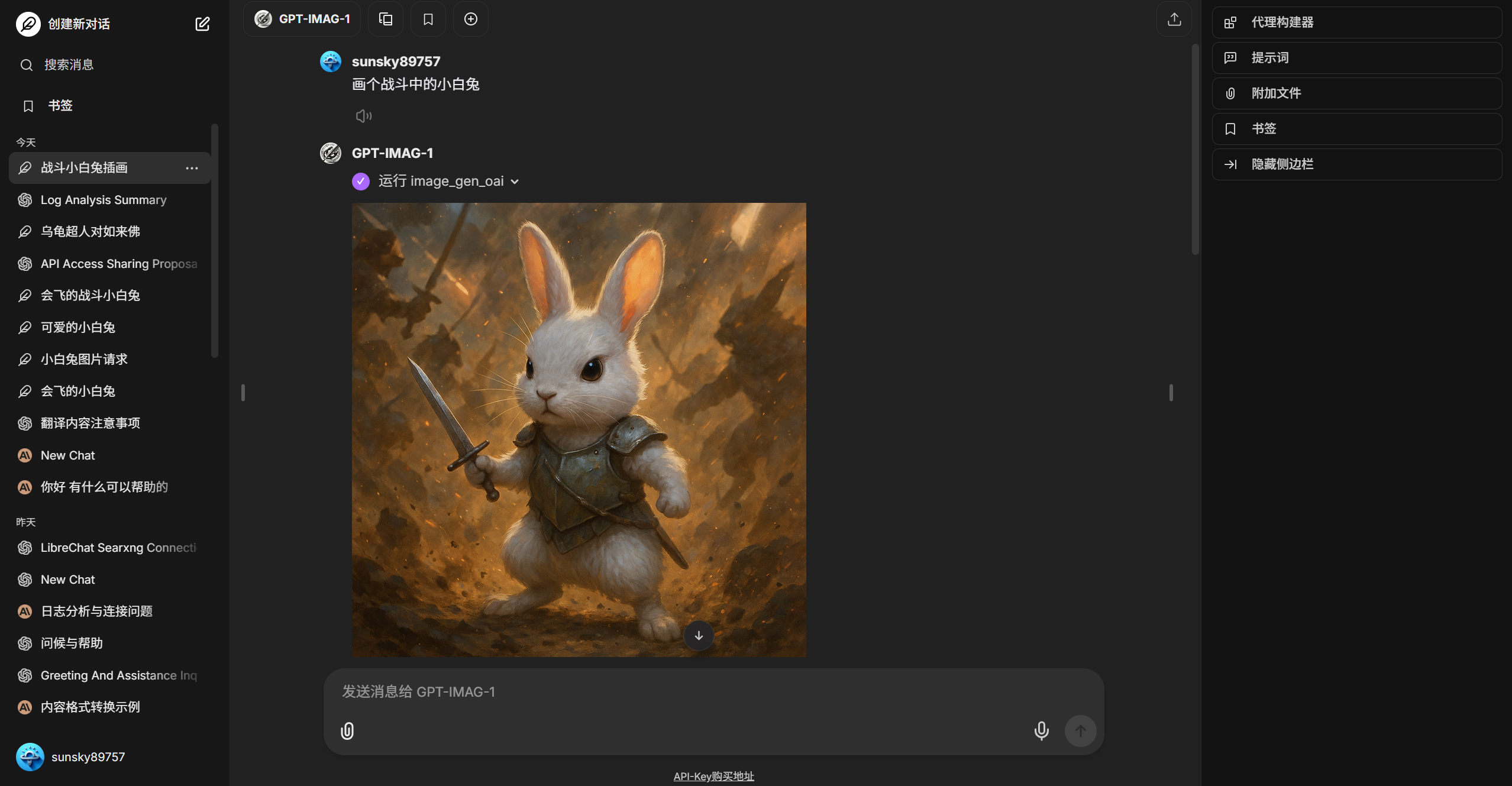
注册并登录JuheNext平台部署的AI应用LibreChat>>,首先需要至少配置OpenAI的API密钥,如下图所示:
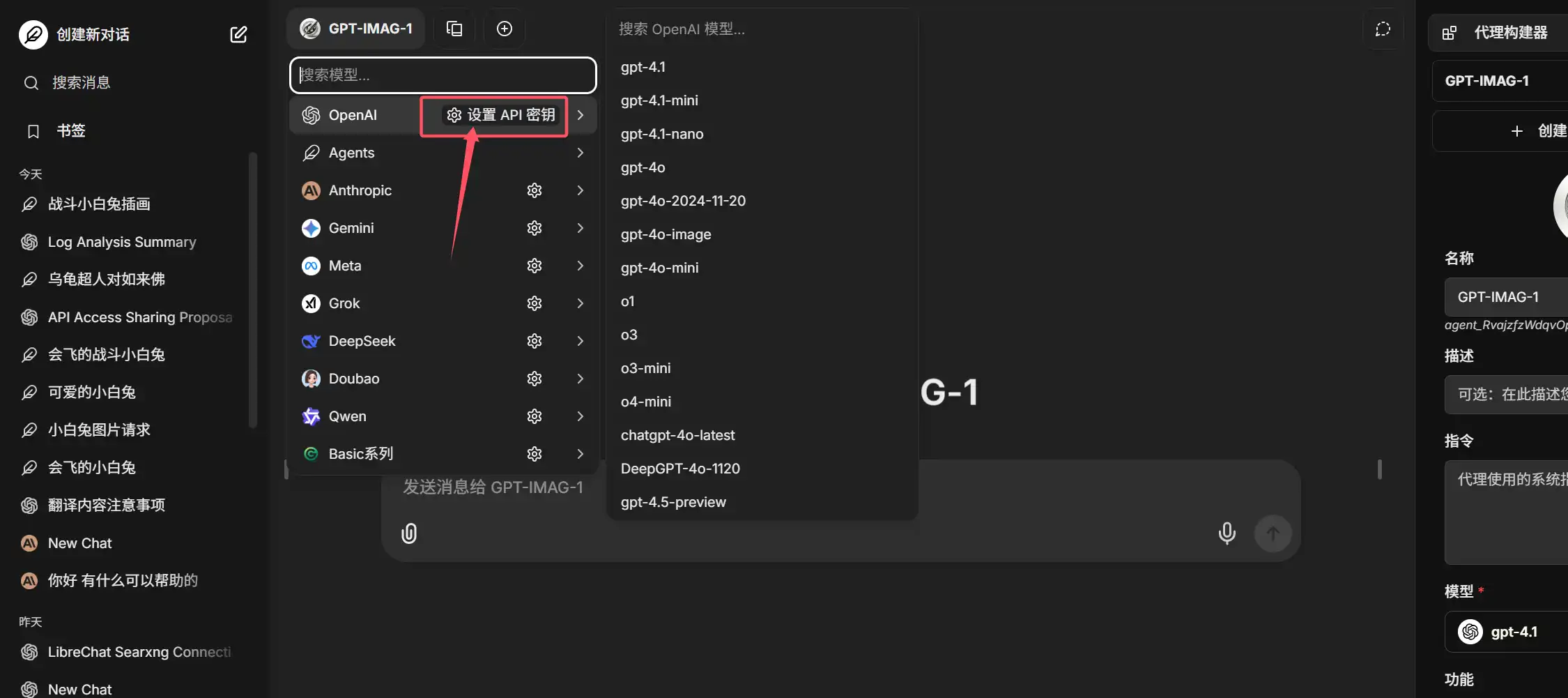
设置后,选择OpenAI分组下任意AI模型,并尝试对话,如果有回复证明设置成功。
然后从右侧侧边栏找到代理构建器,命名为GPT-IMAG-1,并选择OpenAI其中一个模型作为助手Agent的对话模型。
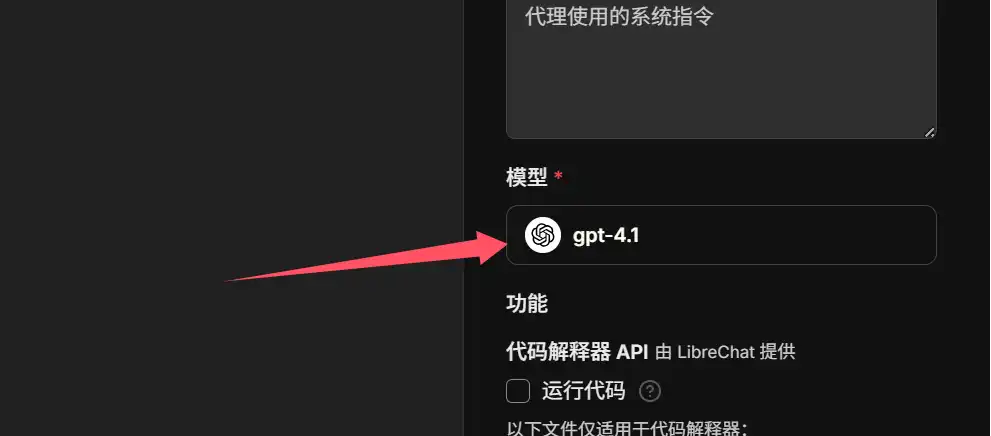
下方工具请按图示添加OpenAI的image模型,添加前请先填写自己的秘钥。
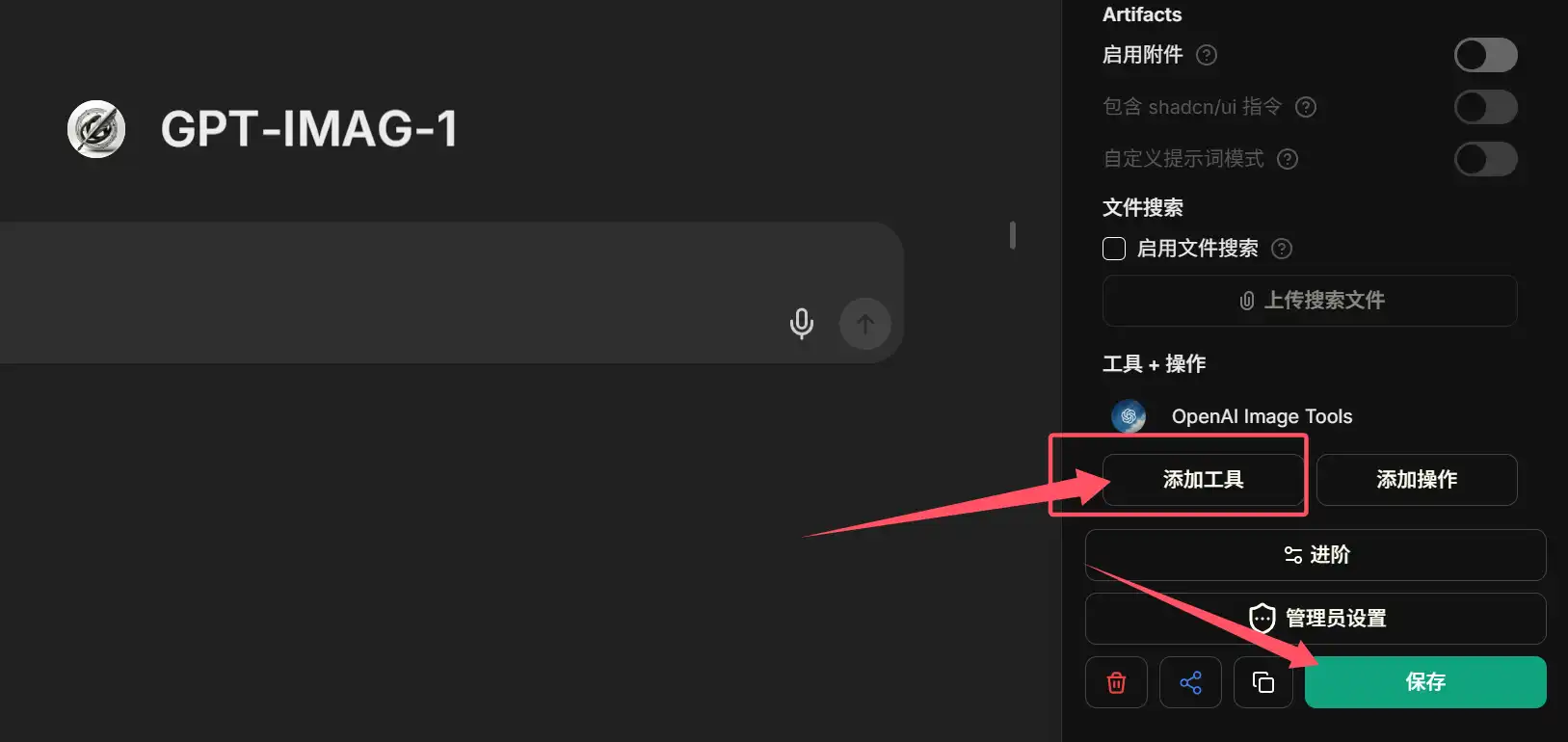
保存即可。
绘图模型支持图像生成和图像编辑两种功能,两者都使用 OpenAI 最新的图像生成模型 GPT-Image-1,以实现优质的指令遵循、文本渲染、详细编辑和现实世界知识。助手中配置的LLM模型会根据用户的请求选择合适的工具:
1、图像生成
从文本提示创建全新的图像(无需上传)。图像生成支持的参数(支持中文描述):
- 提示 – 您的描述(必填)
- 尺寸 – auto (默认), 1024×1024 (正方形), 1536×1024 (横向), 或 1024×1536 (纵向)
- 质量 – auto (默认), high , medium 或 low
- 背景 – auto (默认), transparent , 或 opaque (透明需要 PNG 或 WebP 格式)
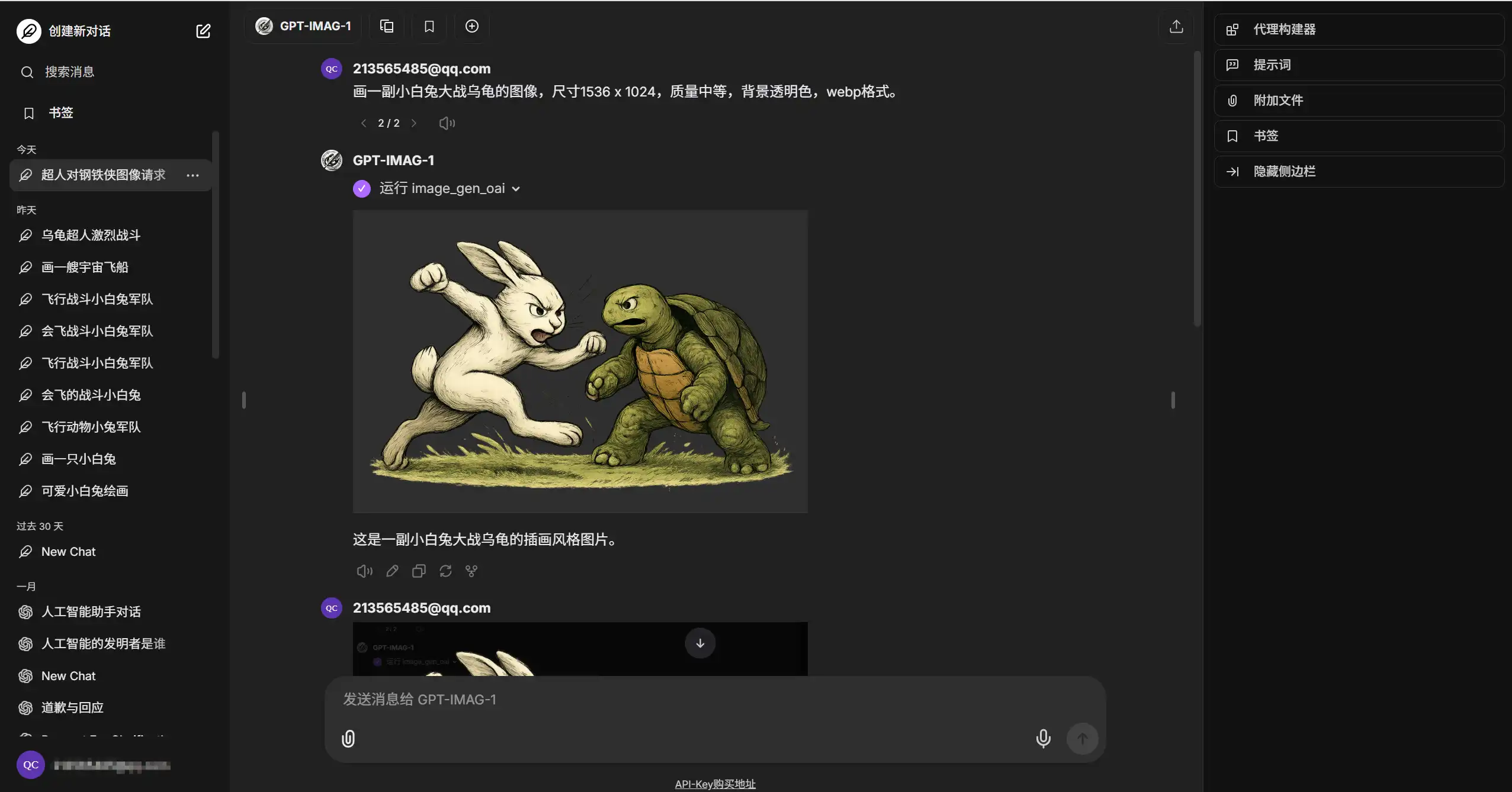
根据你的具体要求,将以上参数转换为自然语言,即可开始生图,例如我使用以下提示词生成的图像:
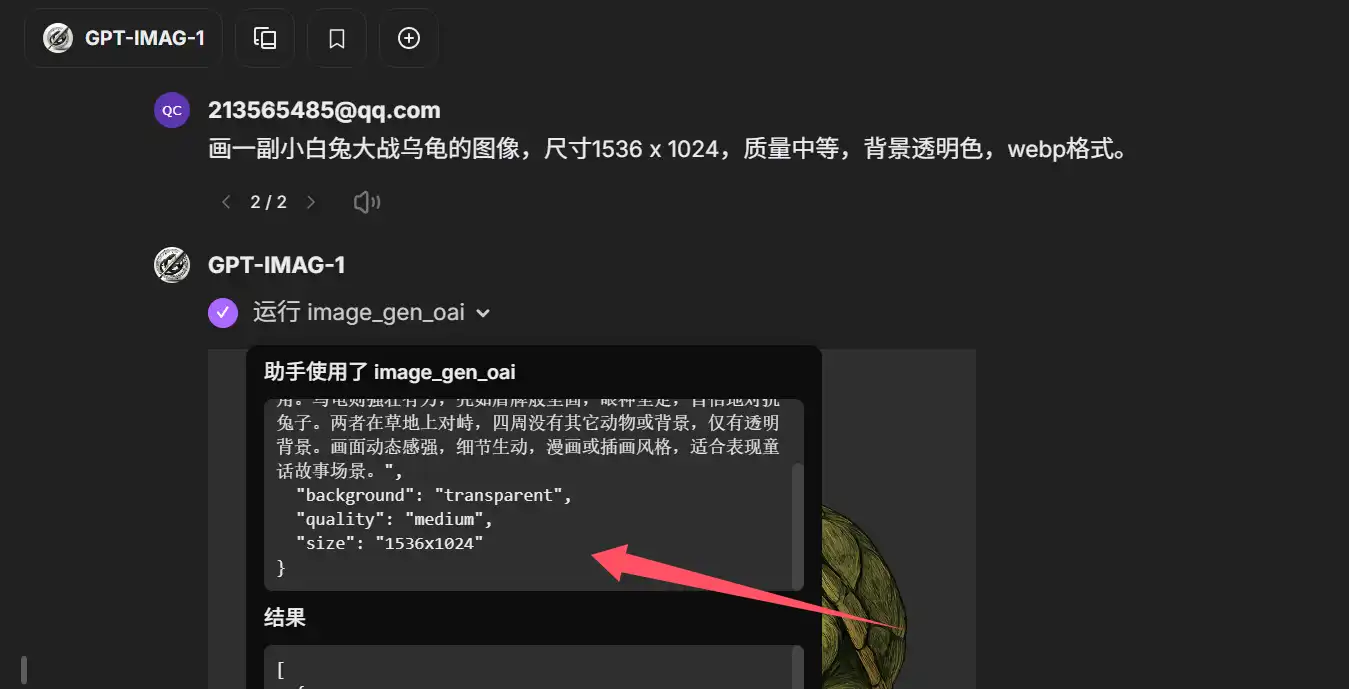
画一副小白兔大战乌龟的图像,尺寸1536 x 1024,质量中等,背景透明色,webp格式。(注意,暂时还无法从LibreChat中获得原图,如1536 x 1024,您将获取到的图片实际尺寸为1152 x 768)。
AI会自动拆分出对应的参数格式:
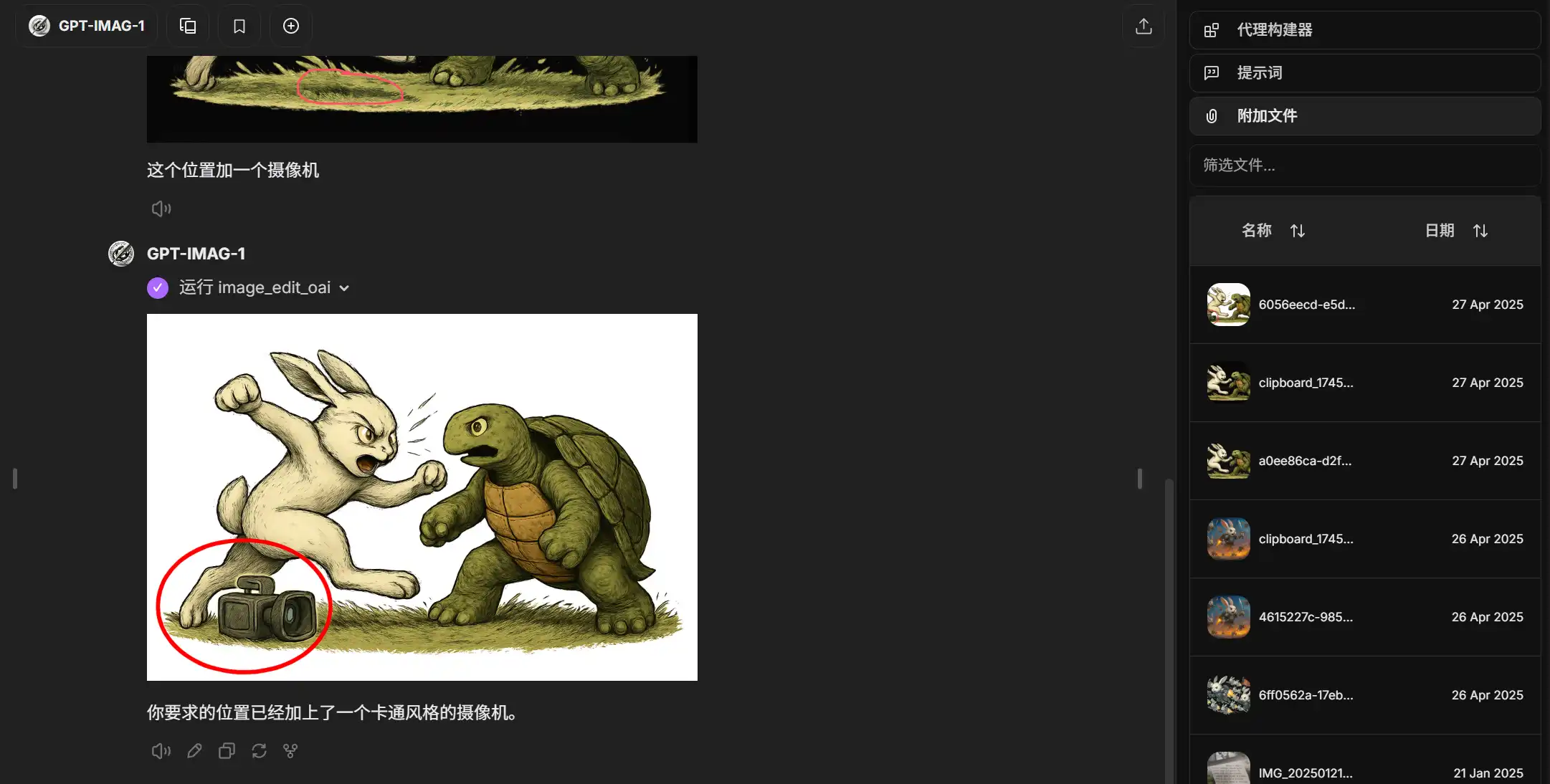
2、图像编辑
GPT-Image-1模型无法实现真正的修改原图,但是会基于原图元素,和你需要修改的要求,参考原图重新绘制图片,以达到改图的效果。
您只需要连续对话,模型会根据现有图像的图像 ID 来修改或重新混合图像。也可以上传图片作为模型生图的前提要求。